系统公告

 问题核实后,平台会赠送头豹点表示感谢
问题核实后,平台会赠送头豹点表示感谢相册选择
图片上传大小不能超过5MB
本报告或文章可用于微博、微信公众号、新闻网站等一般性转载,或用于企业的公开市场宣传,或用于企业投融资咨询、上市咨询等用途。这些引用可能是免费的,也可能产生额外的授权费用,头豹将根据您的引用需求向报告或文章发布者取得相应授权,并派专人与您进一步联系。
请务必如实填写引用需求并按授权范围使用本报告或文章,如头豹发现您最终的引用目的超出所引用需求相应的授权范围,头豹有权要求您停止引用并就头豹因此遭受的损失追究您相应的法律责任。
全文字数:3556字,精读时间:8分钟
本文援引于报告《分布式数据库技术系列概览:分布式数据库核心技术发展趋势》,首发于头豹科技创新网(www.leadleo.com)。
头豹科技创新网内容覆盖全行业、深入垂直领域,行业报告每日更新;政策图录、数据工具助您轻松了解市场动态;智能关键词轻松搜索,直奔行业热点内容。
诚挚欢迎各界精英交流合作,头豹承接行业研究、市场调研、产业规划、企业研究、商业计划、战略规划等业务,您可发送邮件或来电咨询。
客服邮箱:CS@leadleo.com 咨询热线:400-072-5588

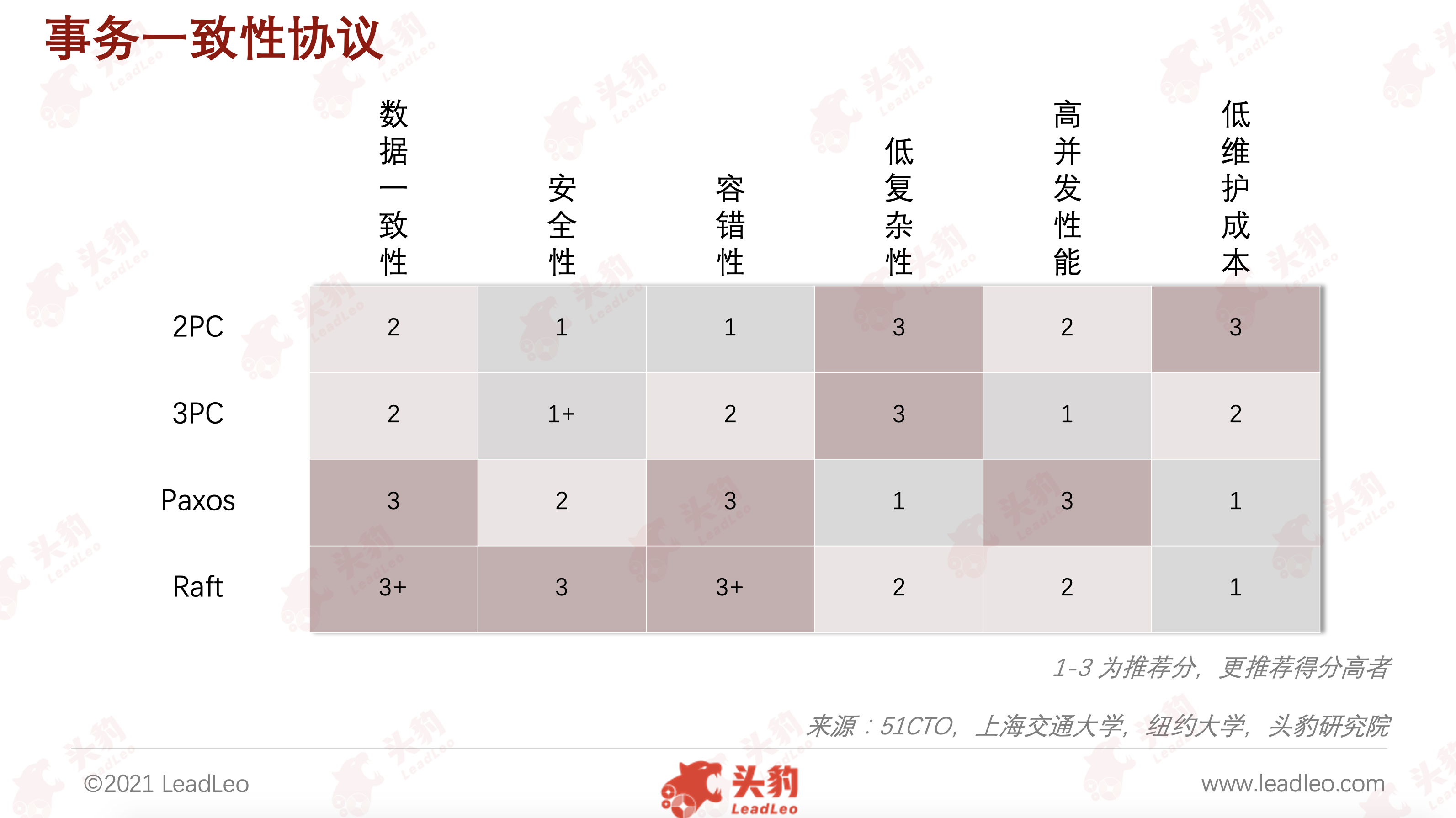
Raft一致性协议在保证数据一致性、安全性、容错性上都有着明显的优势
在数据库系统中通常用事务来保证数据的一致性和完整性。在分布式系统中,数据一致性往往指的是由于数据的复制,不同数据节点中的数据内容是否完整并且相同。不同的业务需求与环境对一致性的要求不一样,金融级需求强调强一致性以保证钱财的安全与一致;互联网需求强调高可用可牺牲一定的一致性以达到性能优先。
CAP理论证明了,任何分布式系统只可同时满足以上两点,无法完全兼顾三者。而分布式系统都需要满足分区容错性,必须在一致性和可用性之间进行权衡。从以2PC为代表的写一致性协议过渡到以Paxos为代表的多数派一致性协议,可应用的分布式事务处理技术走向成熟。分布式数据库以多副本机制来保证系统的安全可靠,而多副本带来的一致性问题则让以Raft为代表的一致性协议成为关键。
无共享架构将成为未来的存储应用主流
对于共享内存架构与共享磁盘架构而言,扩展更多的处理器,反而会使系统减慢,因为增加了对内存访问和网络带宽的竞争,由于内存系统和磁盘系统都由内部通讯机制联系在一起,而出现了明显的瓶颈。
当随着事务数量不断增加,无共享架构通过增加额外的处理器和内存,降低了竞争资源的等待时间,从而提高了性能,保证了每个事务处理时间不变。反过来,如果一个数据库应用系统要获得良好的可扩展的性能,它从设计和优化上就要考虑无共享体系结构。

HTAP混合交易分析型数据库实现在线高并发OLTP及OLAP海量数据分析
OLTP主要用来记录某类业务事件的发生,如购买行为,当行为产生后,系统会记录是谁在何时何地做了何事,这样的一行(或多行)数据会以增删改的方式在数据库中进行数据的更新处理操作,要求实时性高、稳定性强、确保数据及时更新成功。当数据积累到一定的量后,根据业务分析需求从分散的业务系统中提取不同的业务数据,做对应的数据清洗后存储在数据仓库中,然后由数据仓库来统一提供OLAP分析。
OLAP 和 OLTP 系统间会有分钟/小时级的时延,且OLAP和OLTP数据库之间的一致性无法保证,难以满足对分析的实时性要求很高的业务场景。高可用冗余的副本数量大且分散,ETL数据异步传输链路运维复杂度高,副本同步和运维的难度和成本高。软件开发团队需要为不同的数据库编写查询语句,且有可能需要将不同系统的数据进行聚合,开发成本高。
HTAP避免了复杂昂贵的抽取、转换、加载操作(ETL),实现快速分析数据的能力。
HTAP的优点:1.低成本,底层数据可快速复制,并且同时满足高并发的实时更新。2.块连续存储,行存储频繁被修改的热数据,列存储需要查询和分析的冷数据。3.大规模多级并行处理能力MPP ,以无共享架构集群具备线性扩展能力。4.资源隔离,提供AP、TP资源链隔离机制,避免相互影响。

云化与微服务化趋势下,混合云与私有云部署将成为长期暂态
现阶段数据库基于X86环境的分布式架构替代大/小型机环境的集中式架构,并开始逐步迁移各类应用到云平台上,实现数据与业务分离,在保持接口兼容性和数据一致性前提下提供分布式存储与服务能力。
微服务架构是一种将单应用程序作为一套小型服务开发的方法,以使每个应用可独立地进行开发、管理和加速,小团队敏捷交付缩短周期,运营成本大幅下降。随着敏捷开发、持续支付、DevOps理论的实践,以及Docker等LXC(轻量级容器)部署的成熟,微服务架构开始流行。
在微服务化应用开发以及云化平台的趋势下,云分布式数据库调用云基础设施资源将不存在限制,满足了上层应用的弹性扩展、高并发、高吞吐量与灵活敏捷的要求。在中国的金融级需求中,处于核心业务对于数据主权、安全隐私的考量,混合云与私有云部署已成为金融级需求上云的长期暂态。
当云原生使用微服务、容器等技术,赋能数据库更加敏捷的服务支持和更加弹性的扩展及持续的交互;当资源在云基础设施中的调动不受限制,数据处理和分析的服务不再有性能瓶颈和业务可用性的妥协,每个节点既可以管理本地的数据应用也参与全局数据应用,从而构成一个逻辑上统一的数据库系统。将掀起一场数据库领域的代际变革和能力爆发。
运维上云与智能化是适应海量计算环境中保障数据库安全高效得运行的必然发展路线
用户增长与企业投入系统建设维护的成本呈非线性关系,仅增加运维人员的数量无法满足系统发展需求。为了提高IT的整体效率与质量,总结重复、可追溯的现象,形成规则,完成自动运行维护成为发展的必要。
“技术欠账(Technical Debt)”是IT运维团队在代码、技术文档、开发环境、第三方工具、应用冗余和开发实践方面,阻碍变革、降低效率的不足之处。技术欠账可以借助上云实现清晰化,在云上运维中把AI嵌入最关键的业务流程,AIOps通过自动收集和分析基础架构、应用程序和云服务等指标,以及日志和事件等原始数据,通过机器学习分析并从技术角度识别问题。
运维上云是由客户需求驱动服务,服务形式从机房拓展到桌面端、移动端、云端,实行主动式、自动化的工作模式,人员成本低。对比传统IT运维,极大降低了对运维人员的依赖,从故障后处理进阶到故障前规避。
AI算法替代启发式算法,根据现状在运行时进行动态调整,解决传统数据库的痛点
在传统数据库中,大量地使用启发式算法通过传统经验去优化数据库,已然无法满足更高的执行要求,比如针对众多用户的实际场景进行定制化开发。过去采用系统预定义参数组合或可调节参数开关等方式,由DBA根据经验进行调整。
利用AI算法替代启发式算法,解决传统数据库的痛点,典型方向有:
优化器:传统代价优化基于采样统计信息进行表连接规划,存在统计信息不准、启发是连接规划等问题。
参数调优:数据库有数十至上百个可调节参数,其中很多参数时连续值调节空间,依靠人工经验无法找到最优参数组合。
自动化索引推荐和视图推荐:在数据库的众多表与列中自动构建索引和视图,来提升数据库的性能。
事务智能调度:事务的并发冲突时OLTP的难点,可以通过人工智能进行智能调度来提升数据库的并发性能。

开源是发展开发者群体和用户群体以及放大技术影响力的最佳选择,是生态推进的重要手段
开源数据库能够吸引包括ISV独立软件应用开发商、中间件开发商、OS操作系统开发商、服务器/底层硬件提供商的产业链上下游厂商参与,通过免费提供开源版本,企业获取了用户体验的验证,也形成了对外部开发者持续的吸引力。
在需求侧,企业端用户在使用开源数据库作为数据库支撑,可以免除被闭源系统的技术绑定,在开源社区内实现数据库迁移,进行企业需求个性化定制,实现系统间的兼容,解决业务连续性。通过开源确保技术趋于成为数据库行业的主流技术方案。参与国家部门和不同行业监管机构的数据库执行标准的制定,提升自身产品服务能力并符合执行标准,提高用户认可度。
在供给侧,随着开源数据库的流行程度上升,人才供给将源源不断地支持基于开源数据库的不同开发项目,从而进一步扩大开眼数据库的影响力,同时加速开源版本的迭代演进。通过产、学、研、用,打通人才体系建设,通过基础理论对接产业和市场需求构建知识体系,比如openGauss已成为国家计算机等级考试的科目内容,构建良性人才生态,激发产业持续活力。

深度见解:
2010年,甲骨文 Oracle 在最权威的数据库性能测试“TPC-C”中跑出史诗级高分30249688,一骑绝尘超出了死对头 IBM 将近 200%,为数年的缠斗画上钢铁般的句号。
2019年,甲骨文中国大规模裁员。同年,蚂蚁OceanBase跑出了60880800分,时隔九年超越 Oracle 的30249688一倍;华为推出GaussDB,并成功上线招商银行/工商银行核心系统;中信信用卡系统运行在中兴GoldenDB之上。
2015年成立的开源分布式数据库厂商PingCAP,在2021年5月发布了TiDB 5.0,核心代码(自主可控率)100%,其海外市场营收已经超过了国内营收。
数据库软件原本是卡脖子技术,国产厂商已然通过自主攻关打破了甲骨文与IBM的技术垄断。但由于数据库是一个需要下游配套的复杂系统,国产数据库厂商在破局后最重要的是打造生态,加速布局应用端,稳步出海。
相关推荐
2024年中外大模型发展探析(摘要版)
中国大模型市场目前呈现出数量庞大且高度竞争的特点,众多企业和研究机构纷纷涌入这一领域,推出了大量的大模型产品。截至2024年2月,中国已有超过130个大模型出现,创业参与者覆盖各大涵盖开源、闭源、二次开发及微调等,发布机构则遍布互联网科技巨头、云计算领先企业、综合人工智能公司、智能设备制造商以及数字基础设施提供商。然而,与国际厂商相比,中国在大模型技术方面仍存在一定的差距,这主要体现在算法的深度优化、数据处理效率、模型泛化能力以及创新应用场景等方面。 外国的大模型市场虽在数量上不占优势,市面上广为认知的基础大模型不超过10家,但其技术能力却极为强大。以GPT3.5为例,该模型凭借卓越的性能和广泛的应用场景,吸引了庞大的用户群体,其用户数量之多足以证明外国在大模型技术领域的深厚实力。这种实力不仅体现在算法的高效优化和数据处理能力上,更凸显在模型通用性、稳定性以及创新应用领域的开拓上,为中国大模型市场的发展提供了有力的借鉴和学习的目标。
2024年中外大模型发展探析(独占版)
中国大模型市场目前呈现出数量庞大且高度竞争的特点,众多企业和研究机构纷纷涌入这一领域,推出了大量的大模型产品。截至2024年2月,中国已有超过130个大模型出现,创业参与者覆盖各大涵盖开源、闭源、二次开发及微调等,发布机构则遍布互联网科技巨头、云计算领先企业、综合人工智能公司、智能设备制造商以及数字基础设施提供商。然而,与国际厂商相比,中国在大模型技术方面仍存在一定的差距,这主要体现在算法的深度优化、数据处理效率、模型泛化能力以及创新应用场景等方面。 外国的大模型市场虽在数量上不占优势,市面上广为认知的基础大模型不超过10家,但其技术能力却极为强大。以GPT3.5为例,该模型凭借卓越的性能和广泛的应用场景,吸引了庞大的用户群体,其用户数量之多足以证明外国在大模型技术领域的深厚实力。这种实力不仅体现在算法的高效优化和数据处理能力上,更凸显在模型通用性、稳定性以及创新应用领域的开拓上,为中国大模型市场的发展提供了有力的借鉴和学习的目标。
2024年中国数据中心(IDC)产业研究报告
2024年中国数据中心(IDC)产业研究报告
2024年中国元宇宙洞察白皮书:技术突破与模式创新融合发展(独占版)
2024年中国元宇宙洞察白皮书:技术突破与模式创新融合发展
2024年中国元宇宙洞察白皮书:技术突破与模式创新融合发展(摘要版)
2024年中国元宇宙洞察白皮书:技术突破与模式创新融合发展
头豹的程序员小GG强烈建议您使用谷歌浏览器(chrome)以获得最佳用户体验。










