
头豹研究院联合沙利文正式启动大模型行研能力评估测试,现诚挚邀请各企业积极参与,共同探讨中国大模型产业在行研应用方面的现状,助力产业向阳发展。
评测背景
自2022年底ChatGPT向公众发布以来,AI从科技企业的闭门探索正式走向全人类的视界。经过一年的发展,基于GPT起源的大模型技术已成为国家技术和产业的关键战略要素,受到国际广泛高度重视。
当前,基于自然语言处理技术的预训练大模型已在全球范围内掀起了有史以来最大的人工智能浪潮。自ChatGPT推出以来,仅中国地区就出现了超过80个不同的预训练语言大模型,参与者覆盖中国顶尖的学术研究机构以及互联网科技企业,旨在此番浪潮中拔得先机。过去一年中,中国学术与产业界也取得了实质性的突破,来自商汤的商量、百度的文心一言等前沿大模型不断升级,带动中国大模型产业的发展。
基于数字行研解决方案的研究和实践基础,头豹研究院联合沙利文凭借百人分析师团队匿名投票机制,筛选了12个大型模型,进行了多维度的综合评估,旨在全面了解并系统梳理中国大型模型参与者在行研领域的应用表现。

评测介绍
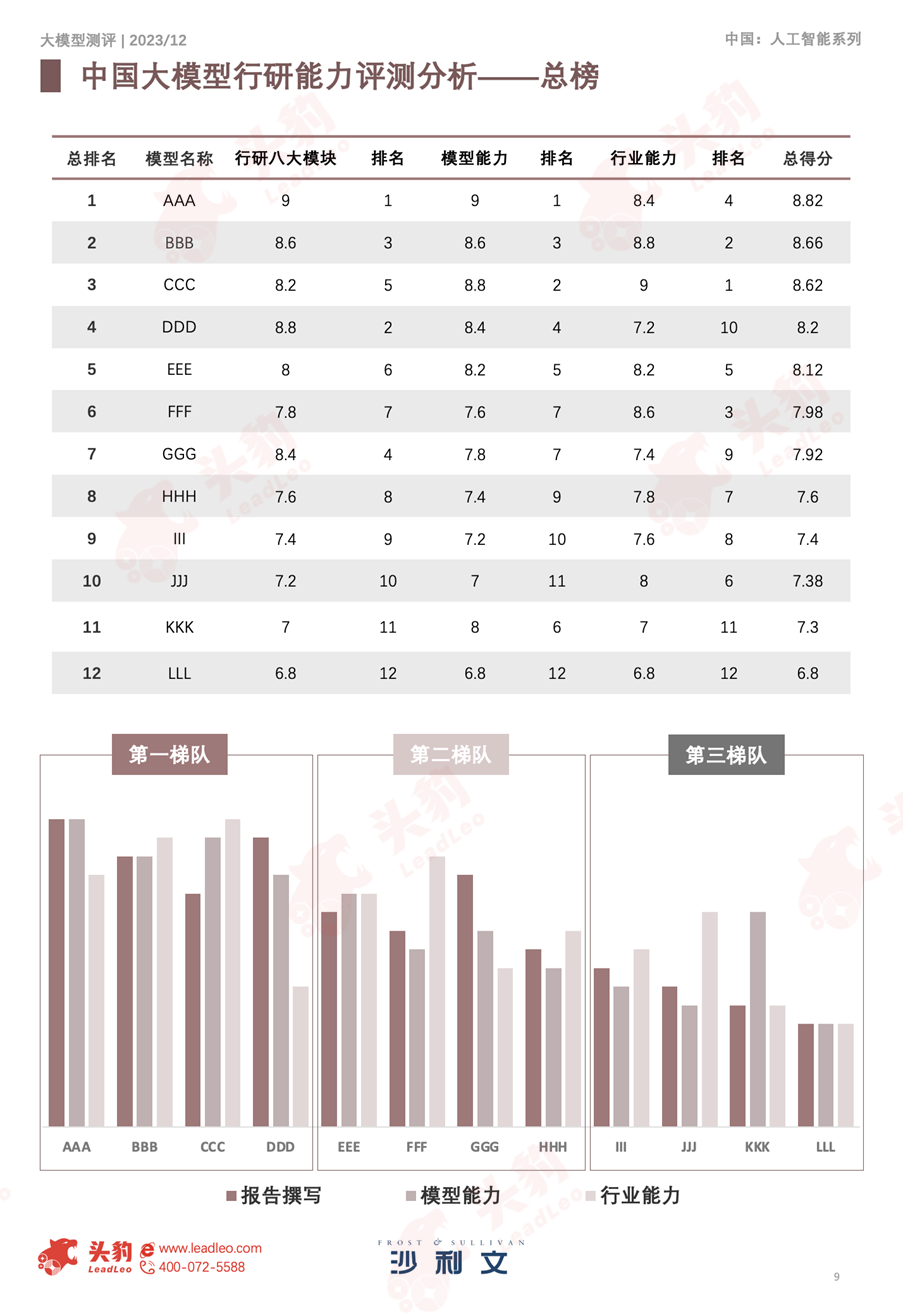
本次语言大模型行研能力测试围绕三大核心板块展开评测:研究报告撰写能力、模型基础能力以及行业综合理解能力。通过模型在三大核心板块的表现力最终得出评测结果。其中,报告撰写方面覆盖8篇不同主题的报告,涵盖128 道问题,分析师长期跟踪的报告问题累积超1,500道题;模型能力方面覆盖6大文本产出核心能力,涵盖54道问题;行业理解方面覆盖14大核心行业,每个行业涉及12个问题,总计168题。三大板块总计超1,800道题目。分析师团队均由头豹研究院及沙利文各团队资深分析师组成,且均具备超过8个月的语言大模型使用经历。评测内容具体包括:
1. 报告撰写能力:
头豹研究院及沙利文联手打造的行企研究8-D方法论,是一种全面而系统的研究方法,包含了八大关键模块,用于对行业进行深入分析。在这一框架下,百名分析师经历了八个月的集中工作与多轮优化,最终研磨出了一套专业的8D模块提问方法,作为评估工具,通过向12个大模型提出问题,来测试和评价模型报告撰写的能力。

2. 模型基础能力:
从AI辅助行研角度出发,结合大模型基础核心能力,归总出对于行研报告撰写角度最重要的六大能力维度。
逻辑推理:逻辑推理是指从已知信息出发,通过推论规则得出结论的过程。在内容评判中,关注信息组织、连接和推导的方式,以及结论是否合理、一致,且基于事实。
类比迁移:类比迁移是指从一个领域或情境中提取概念、原则或模式,并应用到另一个不同的领域或情境。在内容评判中,评估模型在不同概念、情境之间建立联系的能力,以及这些联系的适当性和创造性。
文本生成:文本生成是指创建连贯、相关和有意义的文本内容。在评判内容时,评估文本的清晰度、连贯性、原创性以及语言的正确性和表达能力。
意图理解:意图理解是指识别和理解用户或作者想要传达的目的和动机。在内容评判中,评估信息是否有效地传达了其预期的消息或意图,以及模型是否能清楚地识别这些意图。
知识储备:知识储备是指个体或系统所掌握的信息、事实、概念和理论的总和。在内容评判中,知识储备体现在信息的准确性、深度和广度,以及模型能否正确并有效地使用相关知识。
语境转换:语境转换是指根据不同的交流环境或对象调整信息表达方式。在内容评判中,评估信息是否适应特定的受众、文化背景或沟通场合,以及是否能有效地调整语气、风格和内容以满足不同场景下的写作需求。

3. 行业理解能力:
头豹研究院成立至今,平台共积累超15万+注册用户,6,000+行业及企业研究报告积累,覆盖14个大类行业,以及上千个细分小类行业。在本次大模型评测中,沙利文联合头豹上海、南京和深圳三大研究院,汇聚了跨越多个行业领域的百余名分析师,利用自身对竞争格局、发展趋势、制约因素、以及行业壁垒等关键知识领域的深厚理解,并结合丰富的行业报告撰写经验,向模型提出了针对14个主要行业的细致问题,最终对12大模型在行业理解和内容产出方面进行深度评估。

评测流程
《2023年中国大模型行研能力评测》从研究启动到最终结果呈现分为四个阶段:
第一阶段,模型选择:头豹联合沙利文进行了深入的市场调研,借助数字行研的研究与实践经验,结合分析师团队的投票结果,确定12个大模型作为评测对象。
第二阶段,内容收集:头豹联合沙利文组建报告测评团队,随机匿名分配大模型至团队成员进行大模型测评答案搜集,并将答案交付至评估团队深入分析。
第三阶段,分析师测评:由来自不同行业背景的资深分析师组成的团队,共20人对大模型测评答案进行仔细审阅和评估。为杜绝评测人员的模型偏见问题,答案采用完全随机方式展示,模型名称以代码名称代替,以确保评测人员在审阅时不了解其背后的具体模型。最终,数据分析师对评分结果进行详细的分析和处理。
第四阶段,结果发布:发布《2023年中国大模型行研能力评测》报告结果,并通过多个媒体宣传渠道,包括官方网站、金融服务平台以及公众号等,广泛传达评测报告中的关键发现和深度行业见解,旨在深入向公众传递对中国大模型行研能力的全面理解。
评测规则
基于研究内容独立、公正及客观性的原则,头豹研究院及沙利文评测团队以严格的双盲形式进行评估打分,经过严谨公正的评分规则进行结果产出。
研究计划
《2023年中国大模型行研能力测评》研究启动—2023年10月
确认参选大模型并进行问题涉及以及答案搜集—2023年10月-11月
头豹研究院联合沙利文资深分析师团队评审—2023年11月-12月
《2023年中国大模型行研能力评测》报告发布(预计)—2023年12月
长按识别,参与评测



