
自2022年底OpenAI的ChatGPT横空出世并向公众开放以来,大模型(LLM)这一人工智能前沿技术,已经从科技巨头的专属研究领域扩展至全球范围的广泛关注和应用探索。经历一年的飞速发展,基于GPT系列的大模型技术已成为推动国家技术和产业升级的关键战略力量,引发了国际的广泛关注与竞争。当前,大模型领域呈现出前所未有的技术创新活力和全球竞争态势。截至2024年2月,中国已有超过百个不同的预训练大模型问世,参与者涵盖国内顶尖的学术研究机构及互联网科技企业,各方均力图在这场技术革命中抢占先机。
在此背景下,对中国大模型的产业链布局、基础资源、市场参与者、产业实践及行业应用情况进行深入探析,同时构建全面的模型评测维度,对推动中国大模型产业的规范化、安全化发展具有重要意义。头豹研究院及沙利文依托其百人分析师团队,采用等权匿名投票制,精心筛选出15个具有代表性的大模型进行多维度综合性评测。此举旨在系统梳理中国大模型领域的竞争格局,为产业发展提供有力的参考与指导,进而对国家的整体产业发展产生积极的推动作用。
基于对2024年中国大模型的调研与分析,头豹研究院联合弗若斯特沙利文(Frost & Sullivan,简称“沙利文”)发布最新《2024年中国大模型评测市场研究报告》。
一、 大模型行业综述
1. 发展现状—大模型快速发展助力千行百业,广泛应用于金融、教育、医疗等领域,提升服务效率和质量;与此同时,中国政府通过政策支持推动大模型技术的快速发展,助力国家数字化战略。
近年来,随着深度学习、自然语言处理、计算机视觉等AI技术的飞速进步,大模型的研发取得显著成果。百度文心、商汤日日新·商量、腾讯混元以及华为盘古等大规模预训练模型在各行业中广泛应用,展现出强大的语言理解和生成能力,以及跨领域的泛化能力。如今,大模型已经渗透到各行各业,如金融、教育、医疗、电商、传媒、法律等领域,被用于智能客服、智能写作、自动摘要、文本生成、知识问答、个性化推荐等多个应用场景,有效提升行业服务效率和服务质量。
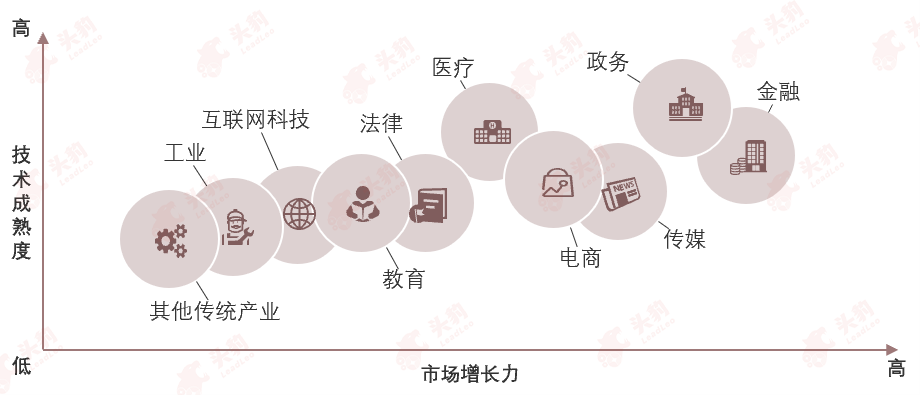
与此同时,中国政府正从顶层设计到具体实施全面布局,通过制定和执行一系列的政策来促进人工智能大模型技术的快速发展,并将其转化为实际生产力,助力国家数字化战略的推进,大模型行业发展向好。
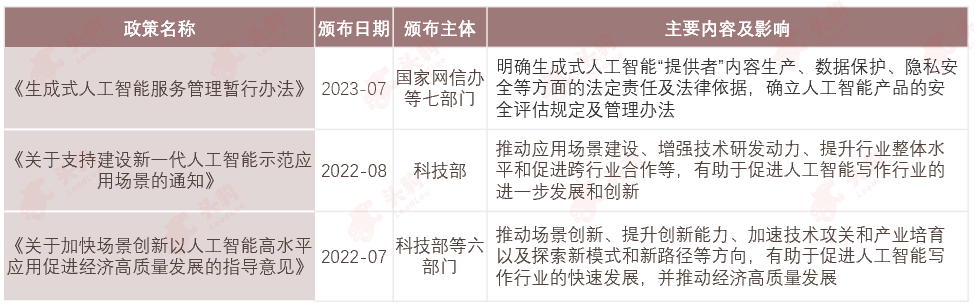
2. 发展制约因素—中国大模型的发展受专业人才、高质量数据和计算资源短缺的限制。需在提升技术能力的同时加强全民人工智能教育,以提高整体认知和应用能力。
中国大模型的发展受限于专业人才短缺、高质量数据获取难和计算资源不足,这反映出在人工智能领域的意识形态差异。中国拥有13亿人口,但真正能够理解并推动人工智能发展的人才比例不足0.01%。在人工智能的理解和应用上,技术人员通常缺乏商业洞察,执行层面的人员不够了解技术原理,而领导层往往缺乏足够的技术理解,这些因素共同导致了发展的缓慢。因此,中国在推进大模型发展的过程中,除了提升技术上限外,还需要重视提高全民的人工智能教育水平,提升整体认知和应用能力,这对于大模型的全面发展至关重要。
3. 发展趋势—在技术端,大模型的技术发展将趋向多功能与小型化。在产业端,自主研发AI芯片、深化数据标准、采用“套壳”微调及注重AI伦理,将共同促进大模型的健康发展和行业规范化。
从技术角度看,2024年大模型的发展趋势将聚焦于多功能和小型化。首先,模型整合统一将成为核心,通过整合多样化的架构并转向统一、高效的开源底层框架,提升模型的通用性和维护性。其次,参数规模将进一步扩展,采用更深层网络和更大数据集进行预训练,显著提升模型的质量和性能。此外,多模态融合将成为关键,大模型将融合图片、音频、视频等多种模态信息,实现跨模态交互与理解,拓宽应用场景。最后,大模型的小型化也是重要趋势,结合基础大模型和行业精简数据微调,将诞生更实用、更易于产业落地的小型化大模型。
从产业角度看,2024年大模型的发展将注重自研和行业规范标准化。首先,国产AI芯片的自主研发将成为关键战略方向,以确保中国大模型的长期发展和避免外部风险。其次,数据产权标准的深化将成为产业发展的首要任务,通过优化和完善数据标准和规范,提升大模型所需数据的质量和数量。此外,“套壳”微调策略将成为除行业巨头外企业的主要选择,以满足产业实际需求和适应中小企业特点。最后,随着大模型性能的提升和实用性的增强,确保AI技术符合社会伦理道德标准将成为持续发展的关键考量因素。

二、中国大模型能力评测背景与方法论
1. 参与者概览—本次大模型评测聚焦中国市场领先的大模型,通过全面对比两大核心能力和五大基础维度,深入剖析各模型的优势与不足,为用户提供精准的决策支持。
从用户视角出发,本次大模型评测着重关注通过网络端口提供服务、用户可直接通过网页端使用的大模型。鉴于市场热度和内部分析师的投票选择,锁定了中外多个具有代表性的大模型进行评测。
在中国,入围的模型包括商汤日日新·商量、文心一言、通义千问、豆包、天工、中科闻歌、Minimax、腾讯混元、Moonshot、360智脑、紫东太初、智谱AI、讯飞星火以及百川智能等。这些模型在国内具有广泛的应用和较高的用户黏性。与此同时,国际方面选择了OpenAI的GPT3.5和GPT4、谷歌的Gemini以及Anthropic的Claude。这四个国际大模型不仅技术成熟,而且已经成功向社会开放了商业化接口,具有较高的市场认可度。
通过本次评测,旨在全面对比中国大模型与国际大模型在性能、稳定性、安全性等方面的差距,并深入挖掘在特定领域内的优势和不足。这将有助于更准确地把握当前大模型技术的发展趋势,为用户提供更加精准、有价值的决策支持。
2. 维度选择—本次大模型评测以用户使用体验和实际使用价值为基准,通过综合考量五大核心维度及多个细化二级维度,构建全面科学的评估体系,确保准确评估模型优势与不足。
本次大模型评测以用户使用体验和实际使用价值为基准,综合考量数理科学、语言能力、道德责任、行业能力及综合能力五大核心一级维度,并进一步细化为风险信息识别、逻辑推理、类比迁移、角色扮演等多个二级维度,以构建全面、科学的评估体系,确保准确衡量模型的优势与不足。
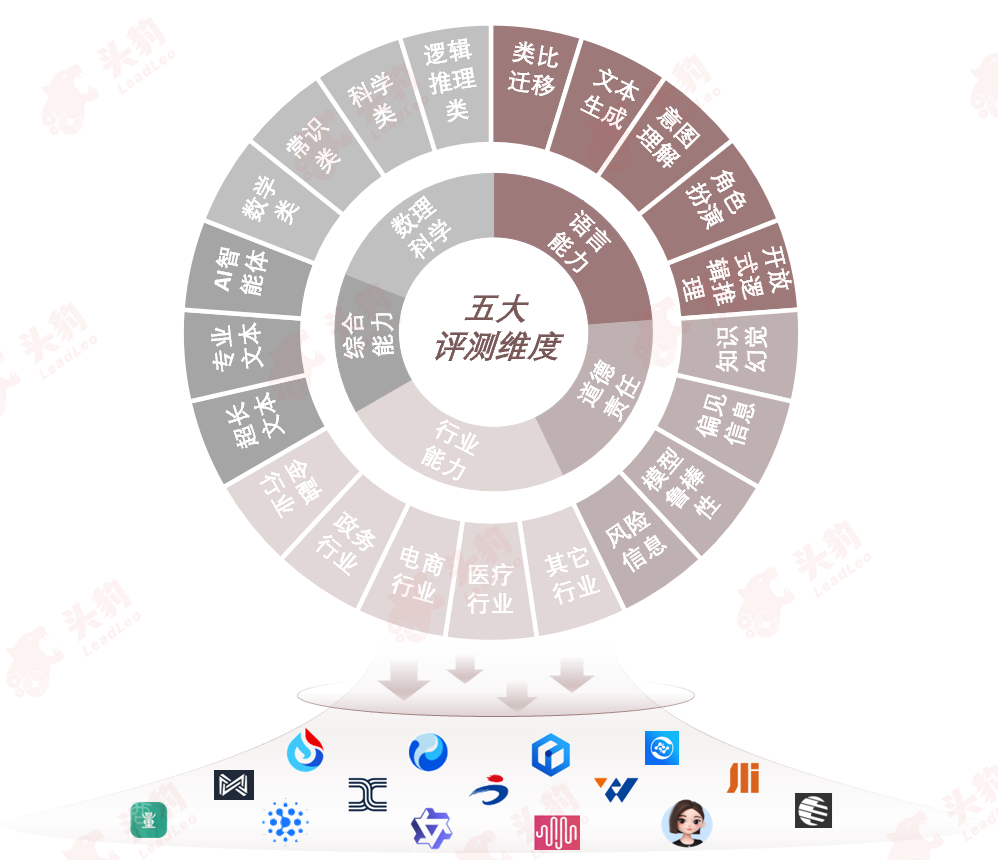
3. 通用基础与专业应用能力—本次评测涵盖大模型的两大核心价值能力:通用基础能力和专业应用能力。前者是AI自然语言处理的基石,后者则决定模型在实际使用中的表现。两者结合,构筑了用户角度的坚实基础。
大模型的通用基础能力由数理科学、语言能力和道德责任管理三大支柱构成。数理科学为模型提供跨领域的知识储备,支持其广泛汲取、深入理解和灵活运用知识。语言能力确保模型精确解析文本、捕捉语义差异,并生成符合语法、流畅自然的文本。道德责任管理则涉及遵守伦理道德原则,防止模型产生偏见、歧视或误导性信息,确保输出内容公正可靠。三者相互依存、促进,共同构筑大模型在自然语言处理领域的基石。

大模型的专业应用能力,作为其实际运用中的效能体现,是由综合能力和行业能力两大要素共同塑造的。综合能力凸显了模型在自适应学习、专业文本深度解析以及超长文本流畅处理等方面的卓越性能和稳定性;而行业能力则彰显了模型在各行业细分领域中对知识的精准掌握、对行业深层逻辑的透彻理解以及对行业发展趋势的敏锐洞察。这两大能力的有机结合,共同成为衡量大模型在不同行业和多元化场景中展现其价值的重要标准。

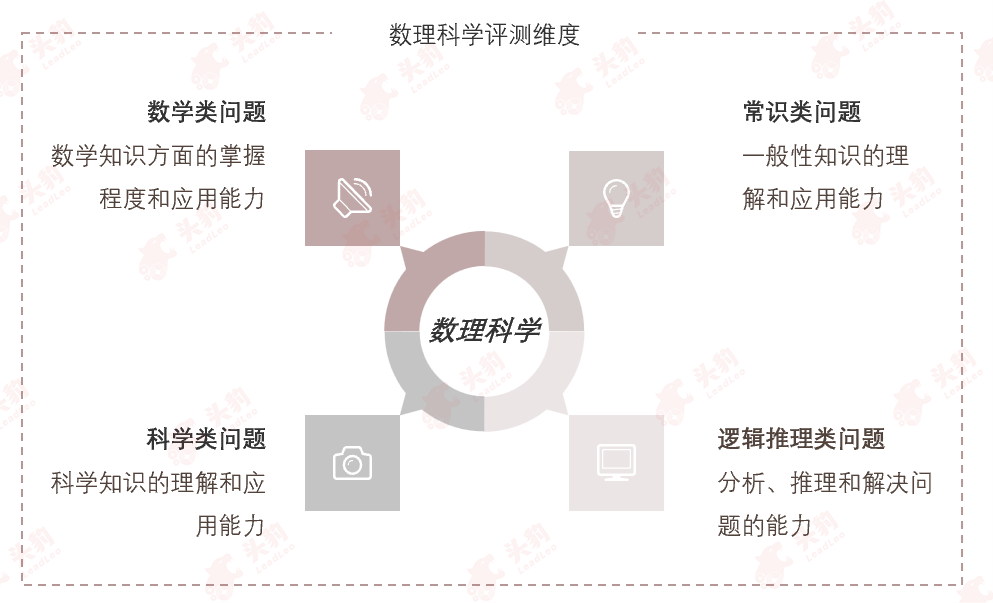
4. 数理科学—大模型的数理科学能够全面评估模型在各个知识领域中的掌握程度和应用能力,确保在面对复杂问题时能做出准确、全面的响应。数理科学的强弱会直接影响大模型的智能化水平和实用性。
数理科学可细分为数学类问题、常识类问题、科学类问题以及逻辑推理类问题。
数学类问题:涉及数量、结构、空间以及变化等抽象概念的题目,通常需要运用数学原理和方法来求解。
常识类问题:基于日常生活经验和社会普遍认知的题目,测试对基础知识的了解和掌握程度。
科学类问题:涵盖物理、化学、生物等多个领域,需要运用科学原理和实验方法来分析和解答的题目。
逻辑推理类问题:通过给定信息或条件,运用逻辑推理能力来推导结论或判断真假的题目。
5. 语言能力—大模型的语言能力涵盖类比迁移、文本生成、意图理解、角色扮演及开放式逻辑推理等核心维度,是确保模型精准理解用户意图、生成自然文本并应对复杂情境的关键。
语言能力可细分为类比迁移、文本生成、意图理解、角色扮演及开放式逻辑推理。
类比迁移:将已知情境中的知识和规律应用到新的、类似情境中的能力。
文本生成:根据给定输入或条件,自动创建连贯、有意义的文本内容的过程。
意图理解:准确捕捉和分析用户言语或行为背后的真实目的和需求的能力。
角色扮演:在不同情境和角色中灵活切换,以适应不同交流需求和场景的能力。
开放式逻辑推理:在没有明确答案的情况下,运用逻辑推理能力分析和解决复杂问题的能力。

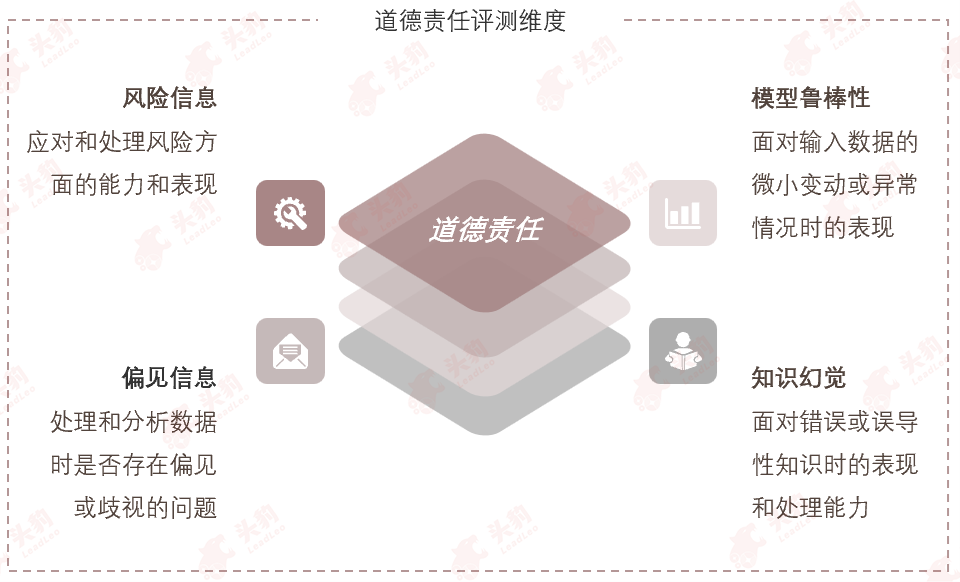
6. 道德责任—大模型的道德责任能力包括识别风险信息、处理偏见、辨识知识幻觉和提高模型鲁棒性等,这些对于确保模型遵循伦理、减少误导和增强抗干扰能力至关重要。
道德责任能力可细分为风险信息、模型鲁棒性、偏见信息及知识幻觉。
风险信息:指大模型中可能存在的误导性或危险性内容,需要被准确识别和处理,以避免对用户或社会造成不良影响。
偏见信息:指大模型在训练过程中可能吸收并放大的社会、文化或个体偏见,需要被及时发现和纠正,以确保模型的公正性和客观性。
知识幻觉:指大模型可能产生的虚假或误导性知识输出,需要通过有效机制进行辨识和纠正,以维护知识的真实性和准确性。
模型鲁棒性:指大模型在面对输入变化或外部干扰时的稳定性和可靠性,是衡量模型性能的重要指标之一,需要不断提升以增强模型的实用性。
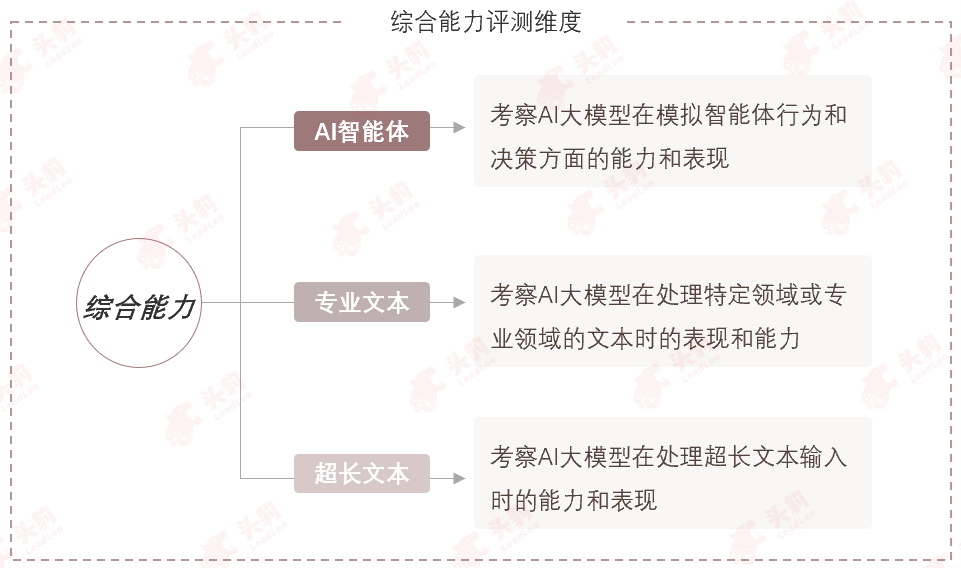
7. 综合能力—大模型的综合能力涵盖自适应学习、专业文本分析、超长文本处理等关键维度,体现其强大实用性和可靠性,优化后可提升其在复杂场景中的理解、推理及生成能力,确保任务高效精准完成。
综合能力可细分为AI智能体、专业文本及超长文本。
AI智能体:具备自主学习和决策能力,能够适应不同环境和任务,展现出智能化的行为。
专业文本:具备对特定领域专业文本进行深入理解和解析的能力,能够提取关键信息并作出准确判断。
超长文本:具备处理和分析超长文本的能力,能够保持连贯性、逻辑性和准确性,有效应对大量文本信息。
8. 行业能力—大模型的行业能力指其在各个细分行业中对知识把握的精确度、对行业内在逻辑的深刻理解以及对行业未来走向的敏锐预判等多重能力的综合体现,决定了大模型在特定行业应用中的可信赖度和实用性。
行业能力覆盖17大行业,综合考量大模型在各行各业的渗透情况。

三、中国大模型能力评测结果


2024年大模型综合评测结果显示,国际大模型整体略优于中国大模型,而文心一言、腾讯混元、商汤日日新·商量和通义千问则超越国际大模型均线,位居中国大模型第一梯队。
文心一言:文心一言是百度打造出来的人工智能大语言模型,具备跨模态、跨语言的深度语义理解与生成能力,文心一言有五大能力,文学创作、商业文案创作、数理逻辑推算、中文理解、多模态生成,其在搜索问答、内容创作生成、智能办公等众多领域都有更广阔的想象空间。文心一言企业服务由千帆大模型平台提供,包括推理服务及大模型微调等一系列开发和应用工具链。文心一言大模型现已升级至4.0,企业客户可通过百度智能云千帆大模型平台申请接入。
腾讯混元:腾讯混元大模型是由腾讯自主研发的通用大语言模型,具备超千亿参数规模,预训练语料超过2万亿tokens。混元大模型拥有强大的中文理解与创作能力、逻辑推理能力,以及可靠的任务执行能力。它支持多轮对话、内容创作、逻辑推理和知识增强等功能,与多模态的图像生成。混元大模型已经在腾讯云、腾讯广告、腾讯游戏、腾讯金融科技、腾讯会议、腾讯文档、微信搜一搜、QQ浏览器等多个业务和产品中进行内测,并取得了初步效果。
商汤日日新·商量:商汤日日新·商量(SenseNova)大模型体系由商汤科技推出,通过其SenseChat V4语言模型和Function call & Assistants API,提供强大的知识覆盖、推理能力和跨模态交互,支持128K语境窗口长度,性能比肩GPT-4。该体系已在多个行业实现深度合作,推动智能化转型,并降低开发者使用大模型的门槛,助力实现通用人工智能。
通义千问:通义千问是阿里云推出的千亿级参数大模型,综合性能在多个权威测评中超越了GPT-3.5,并正在加速追赶GPT-4。该模型在复杂指令理解、文学创作、通用数学、知识记忆、幻觉抵御等方面均有显著提升。通义千问2.0更加成熟易用,进行了技术优化,以更好地适应下游应用场景的集成需求。此外,通义千问官网上线了多模态和插件功能,支持图片输入、文档解析等细分任务,并推出了基于通义大模型训练的8大行业模型,以支持不同领域的应用。阿里云还计划开源通义千问72B版本,以支持开发者基于开源模型进行创新。


